その1 で独自に makeSubList という再帰関数を定義して解決していたが、 fold を使いさえすれば済む話ではないかと思っていたので、今回試した。
結論としては fold で書き直すことができた。
» Read Moreデータを更新するときにありがちな、そのデータのフィールドの一部だけを変更したい場合への各言語ごとの対処方法。
» Read More

覚え書きです。
» Read MoreAngular + React の覚え書きです。 今回は directive 経由で実装します。
» Read MoreAngular + React の覚え書きです。
» Read MoreMac でスクリーン動画を撮ったあとの処理方法のメモ。 作業は Ubuntu 24.04 server LTS 上で行っています。
といっても ffmepg と convert と bash しか使っていないので Mac でもそれらのツールが入っていれば 普通にできる話だと思う。
» Read More
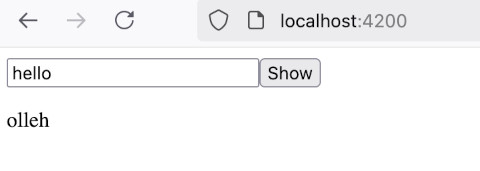
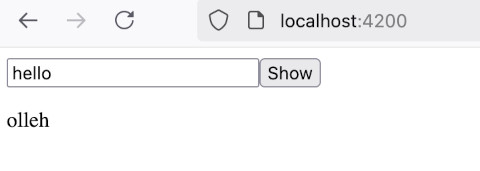
前回作成したコードでは 入力したテキストをひっくりかえすサービスをつくりましたが、 本来この手の処理は Pipe を使う方が Angular 的に自然なので書き直します。 出発点として使うコードは、 前々回作成したコードにします。