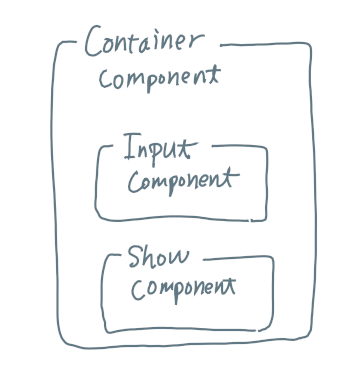

Ubuntu Server + Docker セットアップメモです。 ある意味一番簡単な Docker のはじめかたかもしれない(個人の意見です)。
先月テスト的に余っていたPCにセットアップして、 便利で頻繁に使うことになったので、より高速なマシンにセットアップしなおしたのだが、 一ヶ月前やったことを完全に忘れていたので、ここに作業記録を残す。
» Read MoreGraphRAGを試したいと思い調べたところ、 Text2Cypher というものがあり自然言語を Cypher に変換できるらしい。 よくわかっていないのだが、GraphRAGでは この Text2CypherRetriever を使っているらしい: Effortless RAG With Text2CypherRetriever このページの説明では Neo4j にセットアップされたグラフ形式のデータベースが存在していることが前提で、それに対して自然言語で問い合わせを行うと、 Text2Cypher によって自然言語が Cypher のクエリに変換されて(ここで LLM が使用される)その Cypher クエリでデータベースに問い合わせて結果を得る・・・ という流れ。 つまり、そもそも前提として Neo4j に問い合わせしたいデータが入っている必要がある。
» Read More「ググる」時代から「AIで検索する」時代がきた。このポストで試したAI検索は Perplexity です。
草薙から静岡市へ電車で通勤する場合、 JRか静鉄のどちらも使うことができます。 料金が安い方はどっちなんだろうかと思って調べる代わりに AIに聞いてみました。
使用したプロンプト:
「静岡市 to 草薙(JR) vs 静岡市to県立美術館前(JR) で6ヶ月定期を買う場合の料金を比較したい」
Angular 覚え書きです。
» Read More以前のポスト PostgreSQL データベースのバックアップとリストア の続きです。 docker run していた Postgres のコンテナを破棄すると そのコンテナ内のデータベースの内容も消えます。 その方が都合が良いことも多いのですが、そうではなく維持したい場合について調べた。
» Read MorePostgres をホストOS上 に直接入れないで、Docker で使いたい。 しかし、Docker で動かしている Postgres に psql コマンドなどで アクセスしようとするとき -h localhost を省略することができない。
» Read More前回のポスト PostgreSQL データベースのバックアップとリストア ではデータベースに一つのテーブルしか存在していなかったので、 今回は複数(2つ)のテーブルがあった場合にどうなるか調べてみます。
例によって PostgreSQL を Docker で動かして、ディレクトリ形式でのバックアップとリストアを試します。
» Read More前回のポスト PostgreSQL を docker run する、そこに psql コマンドや Kotlin でアクセスする からの続きです。 PostgreSQL を Docker で動かして、ディレクトリ形式でのバックアップとリストアを試します。
» Read MorePostgreSQL を Docker で動かして、そこに Kotlin Script からアクセスする覚え書きです。
» Read More